
Counter measures for Automatic Speaker Verification Replay Spoofing Attack: OnDataAugmentation,FeatureRepresentation,ClassificationandFusion
相比与真实语音,录制播放语音具有更高的混响。
制造spoofing数据:加混响,phaser
特征提取: CQCC
CQCC提取流程:
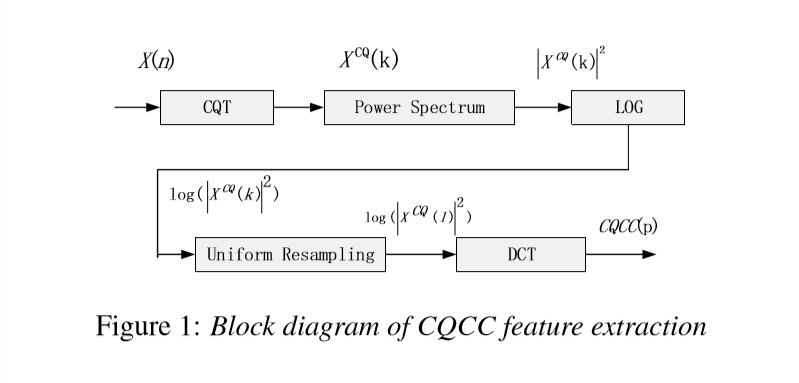
传统CQCC-GMM与该模型的区别:
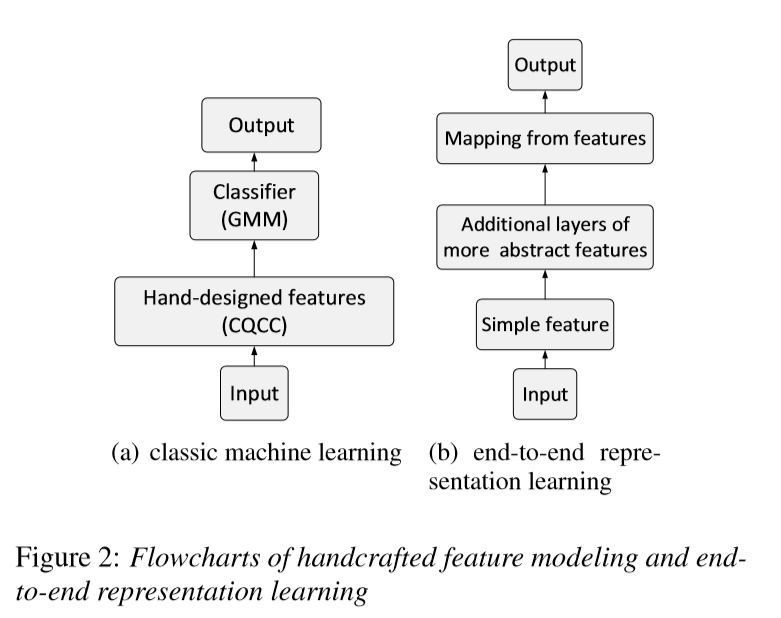
ResNet34:(代替CQCC+GMM):
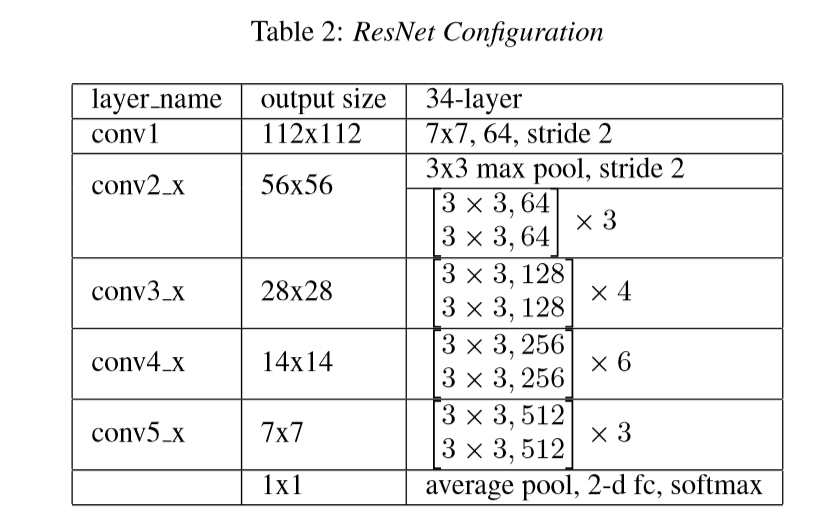
ResNet 输入为224*224 从频谱中利用STFT提取的向量
输出:???
分类模型(需要先提取CQCC):
GMM
FDNN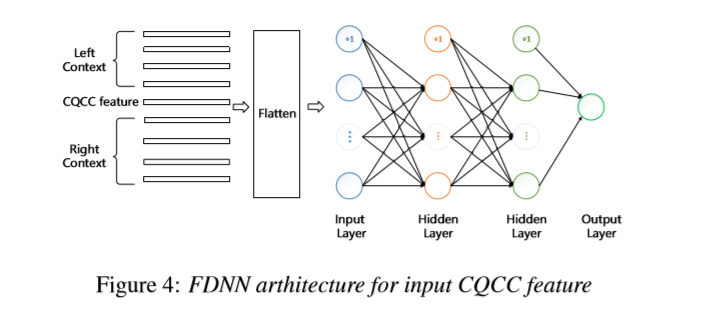
输入:CQCC(当前帧+前后8帧)810
优化函数:交叉熵
输出:0/1
最终得分根据帧级后验概率的mean pooling得到
BLSTM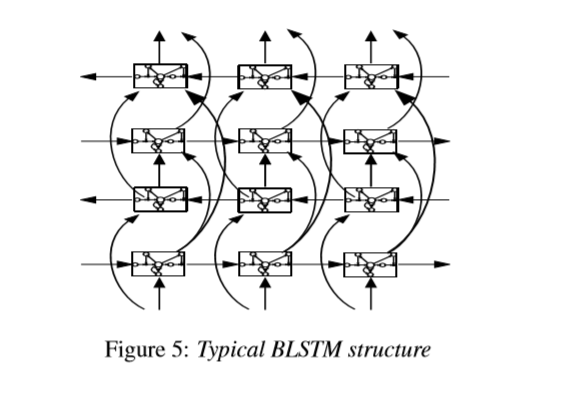
关于RNN,LSTM :https://zhuanlan.zhihu.com/p/32085405

